Recently researched at the MIT Laboratory for Computer Science and Artificial Intelligence (CSAIL) and the MIT-IBM Watson AI Lab suggested Hardware-Aware Transformers (HAT), an AI model training technique that incorporates Google's transformer architecture. They claim that HAT can achieve triple the inference speed on devices like the Raspberry Pi 4, while reducing the model size by 3.7 times compared to a baseline.
The Google Transformer is widely used in natural language processing (and even some computer vision tasks) due to its state-of-the-art performance. Still, deploying transformers to edge devices remains a challenge due to their computing costs. On a Raspberry Pi, translating a sentence with just 30 words takes 13 gigaflops (1 billion floating point operations per second) and takes 20 seconds. This obviously limits the use of architecture for developers and companies that integrate voice AI into mobile apps and services.
The researchers' solution uses Neural Architecture Search (NAS), a method for automating AI model design. HAT conducts a search for transformers optimized for peripheral devices by first training a transformer supernet – SuperTransformer – that contains many sub-transformers. These sub-transformers are then trained simultaneously so that the performance of one provides a relative performance approximation for different architectures that have been trained from the ground up. In the final step, HAT performs an evolutionary search to find the best subtransformer when hardware latency is limited.
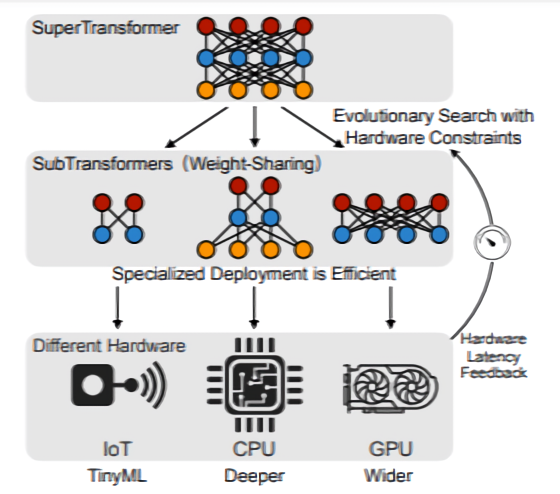
To test HAT's efficiency, the co-authors conducted experiments on four machine translation tasks consisting of 160,000 to 43 million pairs of training sets. For each model, they measured latency 300 times and removed the fastest and slowest 10% before averaging the remaining 80% they had on a Raspberry Pi 4, an Intel Xeon E2-2640, and an Nvidia Titan XP – graphic run map.
According to the team, the models identified by HAT not only achieved lower latency on the entire hardware than a conventionally trained transformer, but also achieved higher scores in the popular BLEU language benchmark after 184 to 200 hours of training on a single Nvidia V100 graphics card. Compared to Google's recently proposed Evolved Transformer, a model was 3.6 times smaller, with a whopping 12,041 times lower computing costs and no performance loss.
"To enable low latency inferences on hardware platforms with limited resources, we suggest designing HAT with neural architecture search," wrote the co-authors, noting that HAT is available in open source on GitHub. "We hope that HAT can pave the way for efficient transformer deployments for real-world applications."